Redes neuronales en la programación del ajedrez informático
Durante mucho tiempo, en el ajedrez informático, se trabajaba con enfoques basados en reglas. Estos programas utilizaban una serie de reglas y heurísticas codificadas para evaluar las posiciones de las partidas de ajedrez y para seleccionar las mejores jugadas.
El punto de inflexión llegó con el éxito de AlphaZero, un programa de ajedrez desarrollado por DeepMind (socio de Google). AlphaZero empezó sólo con las reglas codificadas de cómo se pueden mover las piezas en el tablero y cuándo se acaba una partida, por ejemplo, por tablas o mate. AlphaZero adquirió el resto de los conocimientos completamente por su propia cuenta. Los conocimientos adquiridos durante este entrenamiento se almacenaron en las llamadas "redes neuronales artificiales". Estas redes se utilizaron posteriormente en la partida contra el módulo Stockfish para evaluar las posiciones. En pocas palabras, las redes neuronales se encargan de seleccionar la mejor jugada en una posición determinada.
El resultado de la partida entre AlphaZero y Stockfish demostró claramente la ventaja que tienen las redes neuronales sobre las reglas codificadas. Mientras tanto, todos los desarrolladores de módulos (incluida la comunidad de Stockfish) han seguido su ejemplo e integrado redes neuronales en sus módulos de ajedrez. Probablemente, todos los lectores ya hayan jugado o analizado alguna vez con a un módulo de ajedrez que trabaja a base de una red artificialmente inteligente de este tipo. Aparte de la mejora de la fuerza de juego del módulo, no se suele notar.
Pero, ¿qué exactamente son las redes neuronales? ¿Cómo funcionan, cómo se entrenan y cómo se utilizan en los módulos de ajedrez? He estudiado estas cuestiones e intentaré responderlas en este artículo. Para ello, primero explicaré los principios básicos utilizando una red neuronal "mínima". En la segunda parte, mostraré cómo se pueden aplicar los principios correspondientes a la programación de ajedrez. Como ejemplo, he elegido el final rey y torre contra rey. A primera vista parece sencillo. Pero el reto está en los detalles. Si no se lo cree, podrá probar a programar las reglas correspondientes (sin el uso de las tablebases).
Observaciones preliminares
Cuando se escribe un artículo sobre un tema tan complejo como el de las redes neuronales artificiales, existe el riesgo de que todo se ponga muy técnico y entonces se pierden los detalles. Por eso, he optado por el siguiente enfoque.
En el artículo, describiré mi planteamiento de tal forma que (espero) que sea posible seguirlo sin tener conocimientos técnicos profundos previos. Los términos técnicos utilizados se explicarán en el glosario que figura al final del artículo.
Para quienes estén interesados en los aspectos técnicos de la programación, proporcionaré enlaces al código del programa. Esto se hará en forma de cuadernos Colab. Estos cuadernos son algo así como ordenadores virtuales que se pueden manejar a través del navegador de Internet. Al pichar en los enlaces proporcionados, podrá ejecutar el código Ud. mismo a través de "Runtime -> Select all". Si leinteresa, podrá cambiar los parámetros y ver qué ocurre. No necesita tener ninguna inhibición. Nada se puede romer y es gratis.
Una red neuronal sencilla
Veamos primero cómo se estructuran las redes neuronales. Una red de este tipo se compone inicialmente de nodos, llamados neuronas. Por regla general, estas neuronas se organizan en capas. Cada red tiene al menos un nivel de entrada y otro de salida. Entre la entrada y la salida suele haber un número indeterminado de niveles ocultos.
Las neuronas de un nivel están conectadas a las del nivel siguiente. Existen varios métodos para organizar estas conexiones. Sin embargo, aquí asumimos que cada neurona de un nivel está conectada a todas las neuronas del siguiente nivel.
A las conexiones se les asignan pesos que influyen en la intensidad con la que una neurona influye en la neurona correspondiente del siguiente nivel. En nuestra red mínima, los pesos son factores por los que se multiplica el valor del nodo de origen antes de que el valor se transfiera al nodo de destino. Todos los valores de entrada se acumulan entonces en el nodo de destino.
Un ejemplo sencillo de una red neuronal de este tipo consistiría en una capa de entrada con dos neuronas y una capa de salida con una neurona. En este ejemplo no se utilizan capas ocultas.
El campo de aplicación de esta red podría ser, por ejemplo, un experimento de las clases de física en el que nosotros mismos fijamos dos variables de entrada (X1 y X2) y luego medimos un valor de salida (Y). Los datos podrían tener este aspecto:
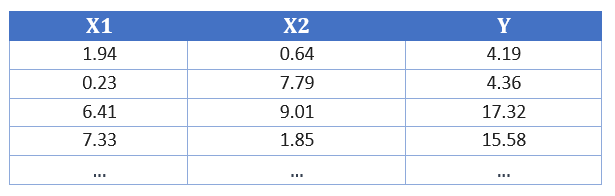
Figura 1: Valores medidos
La tarea consistiría ahora en predecir qué valor tiene Y si, por ejemplo, fijamos X1=10 y X2=20. ¿Cómo debería ser una red neuronal con la que pudiéramos hacer la predicción? Para ello, creamos un nuevo Colab Notebook, al que podemos acceder a través de este enlace.
El comienzo es sencillo. Tenemos las dos neuronas de entrada X1 y X2 y la neurona de salida Y. No necesitamos niveles intermedios ocultos, así que conectamos tanto X1 como X2 a Y.
Actualmente la red tendría este aspecto:
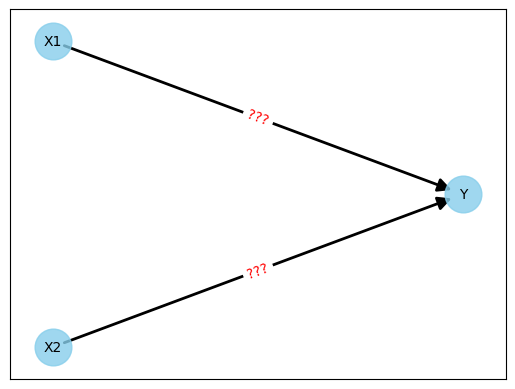
Figura 2: Red neuronal inicial sin pesos
Ahora viene la parte difícil. ¿Qué hacemos con los pesos (mostrados como "???" en la figura)? ¿Cómo deben elegirse estos pesos para que podamos predecir los valores de Y con la mayor precisión posible?
Con las redes neuronales, esto se resuelve con el entrenamiento. Los valores medidos de la figura 1 se utilizan para entrenar la red.
El entrenamiento comienza con los pesos iniciales. Existen distintas estrategias para ello. Por ejemplo, puedes poner todos los pesos a cero o utilizar valores aleatorios. Yo me decidí por los valores aleatorios y obtuve la siguiente red:
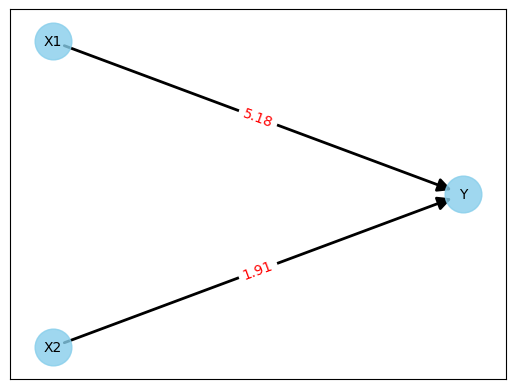
Figura 3: Red neuronal con pesos casuales
Hagamos una prueba rápida con la primera línea de los valores medidos de la figura 1.
Y = 5.18 * 1.94 + 1.91 * 0.64
Y = 11.06
Eso no es bueno, ya que habríamos esperado un resultado de 4,19; así que casi nos hemos equivocado por un factor de 3. Pero podría haber sido mucho peor, ya que habíamos hecho rodar las pesas. Pero podría haber sido mucho peor, ya que habíamos hecho rodar los pesos. De hecho, no importa lo buena o mala que sea la red al principio. El factor decisivo es el entrenamiento (o aprendizaje) de la red.
Ahora veamos más de cerca el entrenamiento. La siguiente secuencia de programas, que he simplificado en gran medida, se ha establecido como la norma en los últimos años:
| Para todos los valores medidos disponibles |
(1) |
| outputs = red neuronal (X1, X2) |
(2) |
| loss = outputs-Y |
(3) |
| do_backpropagation () |
(4) |
| actualizar_pesos () |
(5) |
Figura 4: Entrenando una red neuronal
Breve explicación de estas líneas de código:
- Los siguientes comandos se ejecutan para todos los valores medidos de la Figura 1 (yo había proporcionado un total de 100 pares de valores)
- Este comando calcula los valores de salida. Las entradas son los valores X (es decir, X1 y X2) y se utilizan los pesos actuales de la red.
Calcula la pérdida, es decir, la diferencia entre los valores calculados (salidas) y los valores esperados (y).
- Lleva a cabo la llamada retropropagación. Se utilizan métodos matemáticos para determinar qué pesos son responsables de la "pérdida" en la línea 3.
- A partir de ahí, se calcula la "pérdida". A partir de ahí, se calcula cómo deben ajustarse los pesos.
- Realiza los ajustes de los pesos en la red calculada en el paso 4.
El trabajo principal está sin duda en el paso 4, pero lo bueno es que incluso como programador no tienes que pensar mucho en esto, ya que hay frameworks apropiados como PyTorch, que yo uso, que se encargan de esta tarea.
Si se repite todo cien veces (sólo lleva unos segundos), se obtiene la siguiente red:
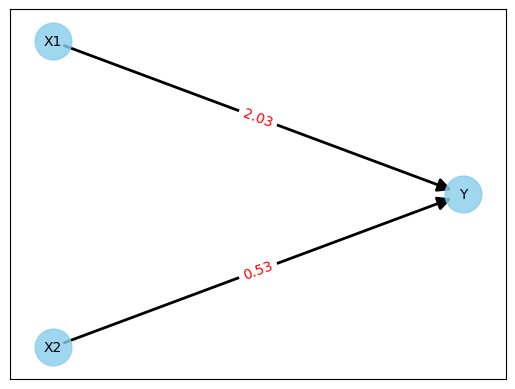
Figura 5: Red neuronal después del entrenamiento
Hagamos de nuevo la prueba con la primera línea de los valores medidos de la figura 1.
Y = 2.03 * 1.94 + 0.53 * 0.64
Y = 4.2774
No es perfecto, ya que el resultado esperado es 4,19. Pero una desviación de 0,08 (aprox. 2%) es suficiente para nuestro pequeño experimento.
Nota: Había generado los valores medidos de la figura 1 con valores aleatorios para X1 y X2 y la fórmula Y = 2,0 * X1 + 0,5 * X2. El resultado perfecto habría sido pesos con los valores 2,0 y 0,5. Si alguien utiliza el cuaderno Colab para volver sobre los pasos, no se sorprenda si salen otros valores. Esto puede ocurrir con números aleatorios.
Una red neuronal para el ajedrez
Pongámonos ahora a la tarea de crear una red neuronal para un motor de ajedrez. La tarea de la red debe ser evaluar una posición de ajedrez lo mejor posible.
El camino desde una red neuronal mínima hasta una red capaz de evaluar toda la gama de posiciones de ajedrez sería demasiado largo y complejo. Por eso he elegido un ejemplo sencillo para este artículo, el apareamiento de rey y torre contra rey. Suena sencillo, pero echemos un vistazo a la siguiente posición:
Figura 6: Posición de rey y torre contra rey (mate en 32 medios movimientos)
En la posición inicial, se necesitan 16 movimientos (o 32 medios movimientos) para dar mate en la mejor partida. Si estableciera esta profundidad de búsqueda en un motor con un algoritmo de búsqueda clásico (por ejemplo, MiniMax), tendría que esperar mucho, mucho tiempo para el primer movimiento, incluso con un buen hardware.
Si fijas la profundidad de búsqueda más baja, tienes que implementar una buena evaluación de la posición. Después de todo, si sólo contara el material, nada cambiaría, ya que las blancas mantendrían su torre extra incluso con jugadas aleatorias (si no lo hace una sola jugada). Por supuesto, hay soluciones establecidas para esto, como puntos extra en la evaluación si el rey negro está cerca del borde del tablero, o la torre blanca corta el camino del rey, etc. Pero esto no es trivial. Pero no es trivial.
Quería adoptar un enfoque diferente con la red neuronal. En lugar de definir reglas explícitamente, quería entrenar un motor simple con una profundidad de búsqueda de un máximo de 3 medios movimientos y sin funciones para la evaluación de la posición, de tal forma que gane la posición anterior incluso si las negras juegan perfectamente.
Los pasos son análogos a los del primer ejemplo, es decir:
Definir la red
- Entrenar la red
- Prueba final
- El paso intermedio "Proporcionar datos de entrenamiento" sigue siendo necesario para el entrenamiento.
Definición de la red neuronal
En primer lugar, veamos cómo transferir la posición de la figura 6 a valores numéricos. Hay muchas formas de hacerlo, pero yo he optado por el siguiente enfoque, que se basa en tablas de bits. Hay un campo separado de 8x8 para cada tipo de pieza. Si el valor es 1, significa que hay una pieza correspondiente en la casilla.
La posición de la figura 5 se representaría así:

Figura 7: Bitboards para la posición de la figura 5
En total, tenemos 3x64 bits, es decir, 192. Se añade otro bit para indicar de quién es el turno (1 = turno de las blancas, 0 = turno de las negras). En total, 193 bits.
A primera vista, los 193 valores de entrada para la red neuronal parecen un derroche, sobre todo porque sólo hay que resolver un pequeño subproblema de la partida de ajedrez. Sin embargo, si echamos un vistazo a la estructura actual de la red Stockfish, veremos que esta red, llamada HalfKA, tiene 91.000 valores de entrada. Sin duda hay buenas razones para ello y el éxito del juego da la razón a los desarrolladores. Pero para nuestro ejemplo, eso sería ciertamente exagerado.
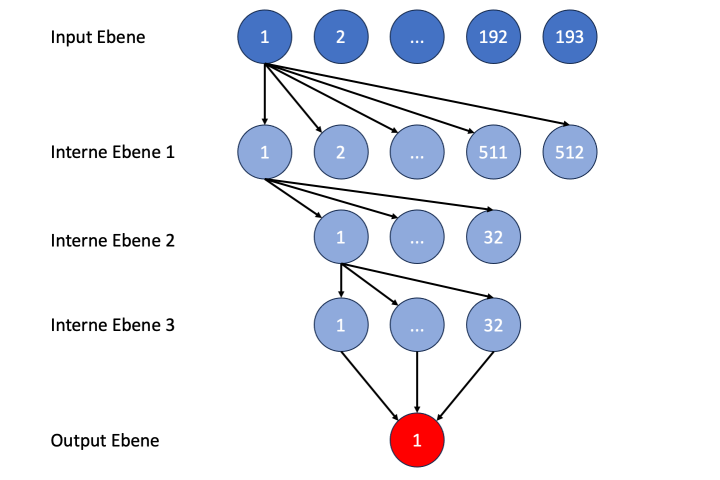
La salida es mucho más sencilla. Se espera un valor numérico que indique a cuántos medios movimientos está la pareja, es decir, un valor entre 1 y 32 (camino más largo a la pareja).
Ahora se requieren niveles intermedios de nodos en esta red. Stockfish utilizaba 3 niveles intermedios con 512, 32 y 32 nodos en la antigua estructura de red llamada HalfKP. No puede estar mal adoptar esto. Nuestra red entonces se ve así:
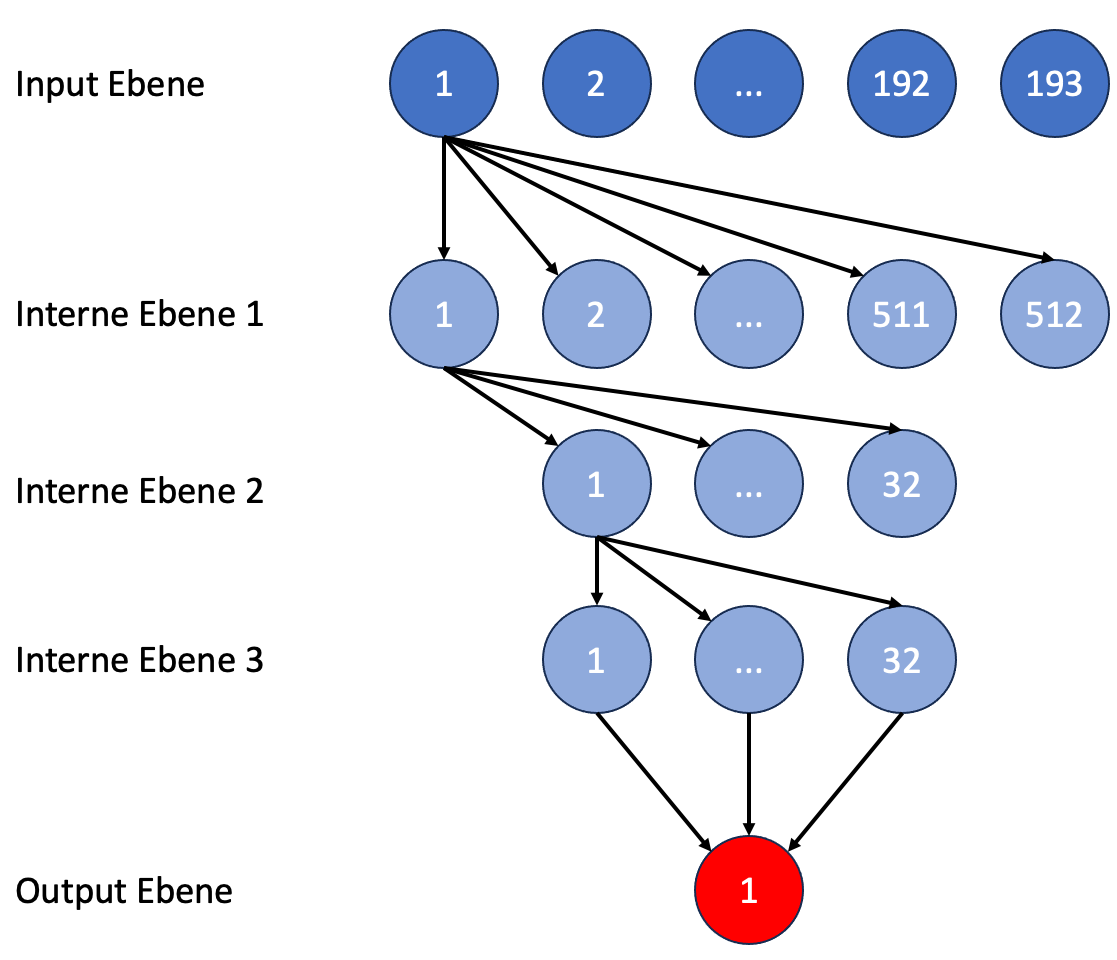
Figura 8: Estructura de la red neuronal para las evaluaciones de posición (los números indican la posición del nodo en el nivel correspondiente)
Suministro de datos de entrenamiento
He creado un nuevo cuaderno Colab para esta tarea, al que se puede acceder a través de este enlace. En este cuaderno descargué primero una tabla base de Internet y luego utilicé un pequeño programa para crear posiciones aleatorias con un rey blanco, una torre blanca y un rey negro. A continuación, utilicé la tabla base para calcular la distancia al mate de cada una de estas posiciones. El resultado fue un archivo con las siguientes líneas:
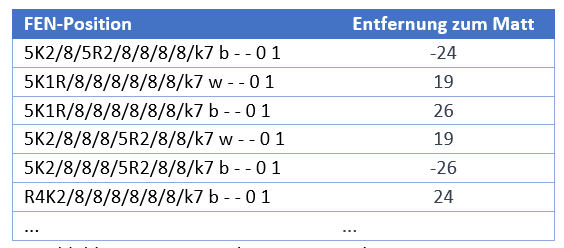
Figura 9: Datos de entrenamiento rey y torre contra rey
Entrenamiento de la red neural
También he creado un Cuaderno Colab aparte para ello, al que se puede acceder a través de este enlace. El entrenamiento funciona según el mismo esquema esbozado en la Figura 4.
He realizado un total de 50 ciclos de entrenamiento (denominados épocas en la jerga técnica) con los datos de entrenamiento generados. En el colab referenciado, la ejecución completa del entrenamiento dura menos de 5 minutos. La siguiente figura muestra el progreso del entrenamiento.
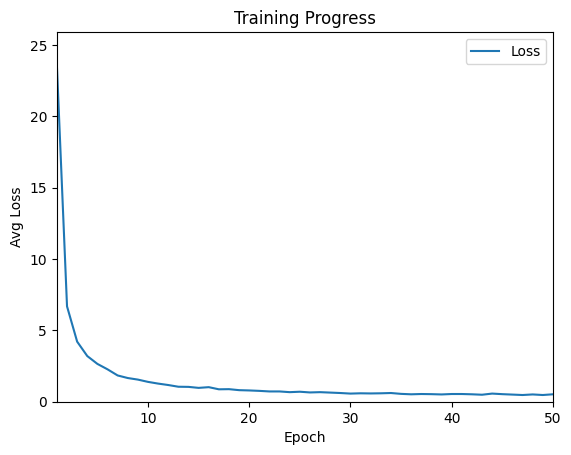
Figura 10: Progresos en la formación
Se puede ver que el progreso es rápido al principio. La pérdida, es decir, el valor en que la evaluación de la red neuronal se desvía del valor correcto, disminuye muy rápidamente. A partir de la época 20, el valor es inferior a 1, tras lo cual el progreso se reduce notablemente. En ocasiones, los valores incluso empeoran ligeramente, pero luego vuelven a mejorar.
La red entrenada de este modo se guarda al final en un archivo (krk_model.pth) y puede someterse entonces a la prueba final.
Prueba final
Ahora ha llegado la hora de la verdad. ¿Es la red entrenada realmente capaz de evaluar correctamente posiciones con rey y torre contra rey?
Sólo hay una forma de averiguarlo. En la posición mostrada en la Figura 6, dejé que la red neuronal (modelo KRk) compitiera contra un motor que siempre selecciona la mejor jugada utilizando la Tabla Base. La red neuronal se integró en la función de evaluación de un motor con un algoritmo MiniMax que utiliza una profundidad de búsqueda de 3 medios movimientos. El código del programa es el siguiente
| def eval (self) |
(1) |
| fen = self.new_board.fen() |
(2) |
| x = get_krk_bitvector(fen) |
(3) |
| eval = self.machine(x) |
(4) |
| return eval |
(5) |
Figura 11: Evaluación de la posición con una red neuronal entrenada
En las líneas (2) y (3), la posición actual del tablero se convierte primero en la estructura de bits conocida de la Figura 7. En la línea (4), se llama a la red neuronal con la posición actual del tablero como parámetro de entrada. En la línea (4), se llama a la red neuronal con la estructura de bits como parámetro de entrada. La salida es la distancia a la pareja, valor que se devuelve en la línea (5). El correspondiente cuaderno de Colab se puede consultar al hacer clic en el siguiente enlace.
El módulo utilizado es muy sencillo. Comprueba todas las jugadas legales de una posición, y a continuación las evalúa, utilizando la función de evaluación de la figura 11. A continuación se selecciona la jugada con la mejor evaluación.
Juguemos ahora con este motor contra un módulo de tablebase:
La red neuronal se debilitó en las jugadas 11 y 12. Sólo el conocimiento de que una triple repetición de jugadas era inminente hizo que la máquina jugara Kd6 en la jugada 13. De lo contrario, la torre habría seguido oscilando entre e6 y e5. De lo contrario, la torre habría seguido oscilando entre e6 y e5. Esta es también la razón principal por la que la red neuronal necesitó 4 jugadas adicionales en lugar de las 16 óptimas. Pero el resultado es impresionante. Sin tener que programar ninguna regla explícita, la red neuronal dio mate rápidamente.
A continuación hice la autoprueba y jugué yo mismo esta posición contra el módulo de la tablebase. Tardé unos 19 movimientos en dar jaque y mate.
Observaciones finales
Se ha cumplido la tarea autoimpuesta de crear y entrenar una red neuronal que permita ganar posiciones con rey y torre contra rey. El motor utilizado para ello sólo conoce las reglas del ajedrez (qué jugadas están permitidas, qué es un mate, qué es una triple repetición de una posición, etc.). La red neuronal se encarga de todo lo demás.
El trabajo no fue tan sencillo y directo como se describe en este artículo. Tuve que experimentar a la hora de definir y entrenar la red y hubo algún que otro contratiempo. Pero cuando me quedé atascado, ChatGPT estuvo ahí para ayudarme y aconsejarme.
A continuación, me gustaría entrenar una red neuronal para todo el espectro de puestos. No faltan datos de entrenamiento. Lichess, por ejemplo, permite descargar más de 90 millones de partidas al mes. Aproximadamente el 10% de estas partidas han sido analizadas por Stockfish y, por tanto, contienen una evaluación para cada movimiento de la partida. Todo ello supondría un esfuerzo mucho más complejo y laborioso que la red descrita aquí en el artículo para las posiciones con rey y torre contra rey. Por lo tanto, estaría encantado de recibir noticias de otros jugadores. Si Ud. se desea poner en contacto conmigo, lo podrá hacer mediante mi sitio web.
Glosario
|
Término |
Definición |
|
AlphaZero |
AlphaZero es un programa informático desarrollado por DeepMind (filial de Google). Es conocido por su éxito en juegos de mesa como el ajedrez, el shogi y el Go. Lo especial de AlphaZero era que solo se implementaban las reglas del juego. Todo lo demás lo aprendió por sí mismo mediante aprendizaje automático. |
|
Bit Board |
Un tablero de bits es una estructura de datos en programación de ajedrez que se utiliza para representar eficientemente posiciones de ajedrez. En lugar de almacenar una posición de ajedrez como una única matriz de 8x8, el tablero de bits utiliza una matriz de 8x8 separada para cada tipo de pieza (rey blanco, rey negro, dama blanca, ..., peón negro). En la matriz de 8x8 para el rey blanco, el valor 1 es para la casilla en la que está el rey y 0 para todas las demás casillas. Las matrices 8x8 para los peones pueden tener hasta ocho unos. |
|
Colab |
Colab, abreviatura de Colaboratory, es un servicio gratuito en la nube de Google que proporciona un entorno de programación Python con bibliotecas para el aprendizaje automático. Colab es muy utilizado en la comunidad de IA, especialmente por quienes no tienen acceso a su propio hardware potente. |
|
FEN |
La notación Forsyth-Edwards (FEN) es una notación estándar para las posiciones de ajedrez. Permite describir una posición en una línea de texto, la llamada cadena FEN.
El software ChessBase proporciona funciones para generar una cadena FEN para una posición o, a la inversa, para crear una posición a partir de una cadena FEN. |
|
MiniMax |
Minimax es un algoritmo utilizado en la teoría de juegos y la inteligencia artificial (IA) para determinar la mejor jugada en un juego de dos jugadores en el que cada uno intenta conseguir el mejor resultado para sí mismo (max) y el peor para su oponente (min). |
|
Neuronales Netz |
Una red neuronal es un modelo inspirado en el funcionamiento del cerebro humano. Está formada por nodos conectados (neuronas) organizados en capas. Se utiliza para aprender patrones y dependencias complejas en los datos y se aplica en diversas tareas como el reconocimiento de patrones, la clasificación o la regresión, entre otras. |
|
Python |
Python es un lenguaje de programación conocido por su legibilidad y simplicidad de código. Fue desarrollado por Guido van Rossum y publicado por primera vez en 1991. Desde entonces, Python se ha convertido en uno de los lenguajes de programación más populares del mundo. Python se utiliza en muchos ámbitos, como las aplicaciones web, la inteligencia artificial, el aprendizaje automático y la automatización. |
|
Python Chess |
Es una popular biblioteca de Python que proporciona funciones para guardar posiciones de ajedrez y generar jugadas legales en una posición. También soporta formatos estándar como FEN (Forsyth-Edwards Notation). |
|
PyTorch |
PyTorch es una biblioteca de aprendizaje profundo de código abierto desarrollada por Facebook AI Research. Proporciona una plataforma flexible para crear y entrenar redes neuronales y otros proyectos de aprendizaje automático.
Si le interesa saber más detalles sobre cómo funciona PyTorch, le puedo recomendar el cursillo de la Universidad de Stanford. |
|
Stockfish |
Stockfish es uno de los motores de ajedrez de código abierto más potentes. El motor es utilizado por ajedrecistas y desarrolladores para analizar y como punto de referencia para otros motores de ajedrez. |
|
Stockfish NNUE |
Stockfish Efficiently Updated Neural Network Evaluation (NNUE) es una mejora del motor de ajedrez Stockfish, que se basa en el uso de redes neuronales para la evaluación de posiciones de ajedrez.
Se puede encontrar una descripción de las estructuras de red HalfKP antigua y HalfKA nueva aquí. |
|
Table Bases |
Las Table Bases, también conocidas como bases de datos de finales, son bases de datos en las que se almacenan todas las posiciones posibles en un final de ajedrez con un pequeño número de piezas restantes. A cada posición se le asigna una evaluación en forma de distancia al mate (si es posible una victoria con el mejor contrajuego).
|
Traducción al castellano: Nadja Wittmann (ChessBase)